array_intersect #
pyspark.sql.functions.array_intersect(col1, col2) #
version: since 2.4.0
Collection function: returns an array of the elements in the intersection of col1 and col2, without duplicates.
Runnable Code:
from pyspark.sql import functions as F
# Set up dataframe
data = [{"a": [1,2,2],"b": [3,2,2]},{"b": [1,2,2]},{"a": [4,5,5],"b": [1,2,2]},{"a": [4,5,5]}]
df = spark.createDataFrame(data)
# Use function
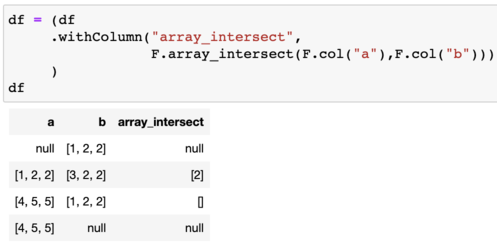
df = (df
.withColumn("array_intersect",
F.array_intersect(F.col("a"),F.col("b")))
)
df.show()
| a | b | array_intersect |
|---|---|---|
| [1, 2, 2] | [3, 2, 2] | [2] |
| null | [1, 2, 2] | null |
| [4, 5, 5] | [1, 2, 2] | [] |
| [4, 5, 5] | null | null |
Usage:
Simple array function.
returns: Column(sc.\_jvm.functions.array_intersect(\_to_java_column(col1), \_to_java_column(col2)))
tags: in both arrays, array intersection, in both lists
© 2023 PySpark Is Rad