array_distinct #
pyspark.sql.functions.array_distinct(col) #
version: since 2.4.0
Collection function: removes duplicate values from the array.
Runnable Code:
from pyspark.sql import functions as F
# Set up dataframe
data = [{"a": [1,2,2],"b": 1},{"b": 1}]
df = spark.createDataFrame(data).drop("b")
# Use function
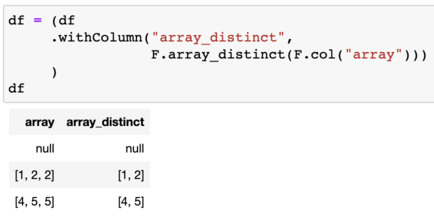
df = (df
.withColumn("array_distinct",
F.array_distinct(F.col("a")))
)
df.show()
| a | array_distinct |
|---|---|
| [1, 2, 2] | [1, 2] |
| null | null |
Usage:
Simple array function. I have used it a lot. Especially when combining two columns of arrays that may have the same values in them.
returns: Column(sc.\_jvm.functions.array_distinct(\_to_java_column(col)))
tags: unique, unique array, unique in list, list, distinct, duplicate
© 2023 PySpark Is Rad